- 注册时间
- 2016-4-12
- 最后登录
- 2016-4-12
- 回帖
- 1
- 主题
- 78
- 精华
- 2
- 金币
- 226
- 威望
- 0
- 股份
- 0
- 热心值
- 0
- 积分
- 228

宝藏初中生
 
- 回帖
- 1
- 金币
- 226
- 威望
- 0
- 积分
- 228
- 股份
- 0
- 热心值
- 0
- 宝藏币
- 0

|
提前祝大家小年快乐吧!本文所用的网址为:www.tingchina.com
[color=]为上班忙里偷闲的人准备
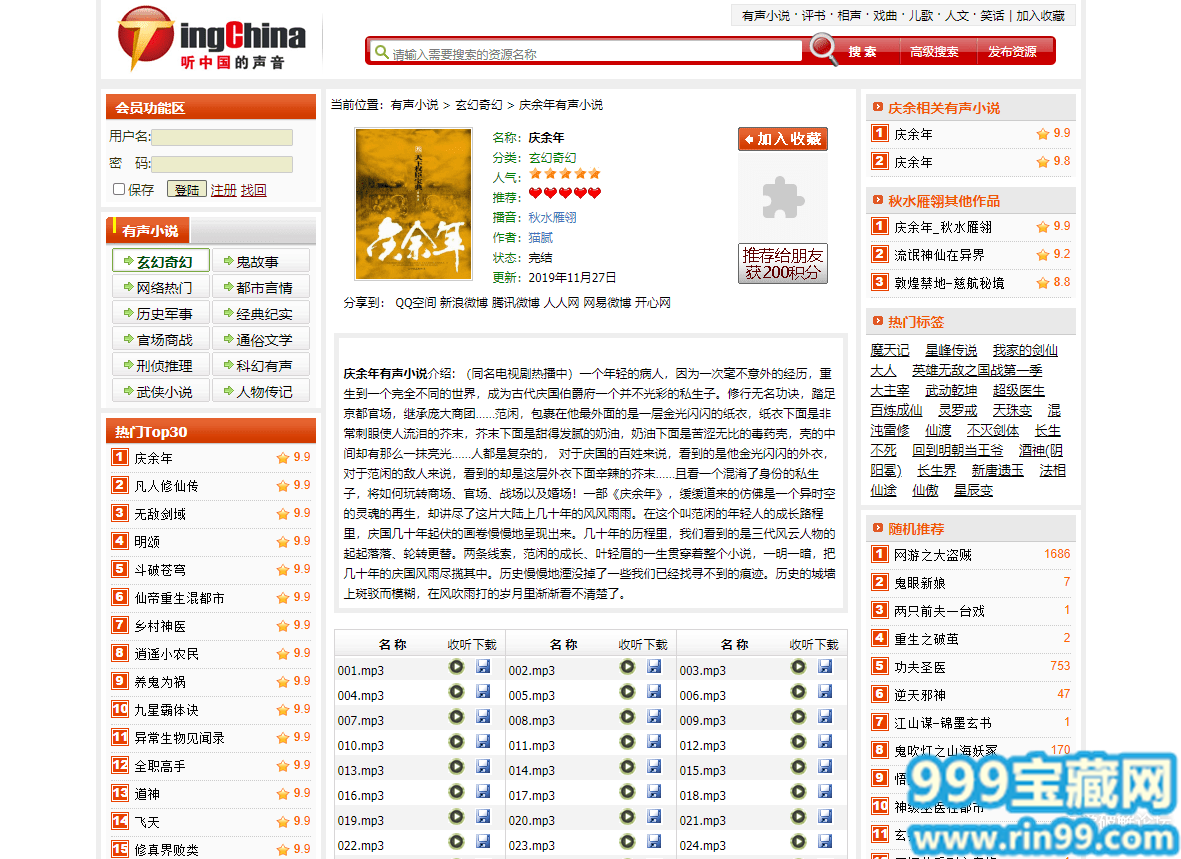
这是一个有声小说打包下载、在线收听、评书、鬼故事、郭德纲相声、笑话等百万有声资源的网站,至今已有十多年,音频资源非常丰富。

在线听限制少一些,但是下载音频到本地就不太行。需要会员,并消耗积分。
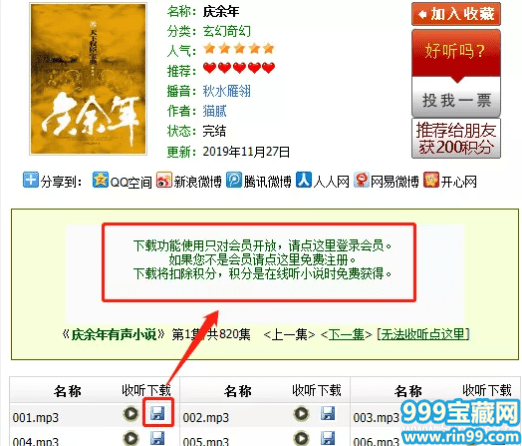
喜欢听音频的兄弟们,可以想办法把网站里的资源下载到本地,放在手机里听,上班摸鱼在电脑上听,就很爽。
今天就给大家分享一个用Python批量下载音频的办法。感谢@天空宫阙@老殁
具体不会的地方私聊。
03Py思路首先,放上源代码:
[Asm] 纯文本查看 复制代码import requests
from bs4 import BeautifulSoup
import re
from tqdm import tqdm
import time
import os
class TingChina():
def __init__(self,id,strat_num):
self.base_url = 'https://www.tingchina.com'
self.id = id
self.num = int(strat_num)-1
self.name_num = int(strat_num)
self.Referer = ''
self.host1 = "http://t44.tingchina.com"
self.host2 = "http://t33.tingchina.com"
self.book_name = ''
def get_total_episode(self):
url ='https://www.tingchina.com/yousheng/disp_{}.htm'.format(str(self.id))
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
}
response = requests.get(url,headers=headers)
if response.status_code==200:
response.encoding='gbk'
soup = BeautifulSoup(response.text,'lxml')
ul = soup.select('div.list > ul')[0]
lis = ul.select('li')
name = soup.select('body > div.wrap03.clearfix > div:nth-child(5) > div.main03 > div:nth-child(2) > div.book01 > ul > li:nth-child(1) > span > strong')[0].string
return name,len(lis)-3
def get_flash_url(self):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
}
url = 'https://www.tingchina.com/yousheng/{}/play_{}_{}.htm'.format(str(self.id),str(self.id),str(self.num))
response = requests.get(url,headers=headers)
if response.status_code==200:
response.encoding='gbk'
soup = BeautifulSoup(response.text,'lxml')
src = soup.select('#playmedia')[0]['src']
self.Referer = url
# print(src)
# https://www.tingchina.com/play/yousheng/flash.asp?id=30391&inum=2&flei=都市言情&bookname=江湖岁月&filename=002_大闯我哥.mp3&rand=16&nexturl=play_30391_2.htm
pattern_params = 'id=(\d+)&inum=(\d+)&flei=(.*?)&bookname=(.*?)&filename=(.*?)&'
match_params = re.search(pattern_params,src)
if match_params:
info = {
'id':match_params.group(1),
'inum':match_params.group(2),
'flei':match_params.group(3),
'bookname':match_params.group(4),
'filename':match_params.group(5)
}
# print(info)
real_address = self.host1+'/yousheng/{}/{}/{}'.format(info['flei'],info['bookname'],info['filename'])
# print(real_address)
return src,url,real_address
def get_audio(self):
'''get key 和 real_address拼接得到可以访问的地址'''
temp_url,Referer,real_address =self.get_flash_url()
# url = 'https://www.tingchina.com/play/yousheng/flash.asp?id={}&inum={}'.format(str(self.id),str(self.name_num))
url = self.base_url + temp_url
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
'Referer': Referer
}
response = requests.get(url,headers=headers)
if response.status_code==200:
# print(response.apparent_encoding)
response.encoding='utf-8'
matched = re.search('url\[3\]= ".*?(key=.*?)";',response.text,re.S)
if matched:
# print(matched.group(1))
return(real_address+'?'+matched.group(1))
def download(self):
url = self.get_audio()
print(url)
if url:
downloadFILE(url,os.path.join(self.book_name,str(self.name_num).zfill(4)+'.mp3'),self.Referer)
def run(self):
name,total_episode = self.get_total_episode()
print('书名:',name,'集数:',total_episode)
self.book_name = name
if not os.path.exists(name):
os.makedirs(name)
while True:
try:
if self.name_num > total_episode:
print('已经下载完成','all assignments done!')
break
self.download()
except Exception as e:
print(e)
with open('log.txt','a',encoding='utf-8') as f:
f.write(str(self.name_num)+str(e)+'\n')
self.num+=1
self.name_num+=1
def downloadFILE(url,name,Referer):
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
'Referer': Referer
}
resp = requests.get(url=url,stream=True,headers=headers)
content_size = int(int(resp.headers['Content-Length'])/1024)
with open(name, "wb") as f:
print("Pkg total size is:",content_size,'k,start...')
for data in tqdm(iterable=resp.iter_content(1024),total=content_size,unit='k',desc=name):
f.write(data)
print(name , "download finished!")
if __name__ == "__main__":
print('例如:20459 1','下载id为20459的有声书从第1集开始下载')
id,start_num = input('请输入id和起始下载集数用空格隔开').split(' ')
if id and start_num:
# t = TingChina(有声书id,起始下载集,如1时从第一集开始下载)
t = TingChina(int(id),int(start_num))
t.run()
else:
print('请输入正确的id和起始下载集数用空格隔开')
然后,我们简单来看看实现过程。
1.总的思路是从flash播放的接口中获得音频的真实地址https://www.tingchina.com/play/yousheng/flash.asp?id=30255&inum=958...

url1或url2和url3拼接就是真实地址。
2.推测由于网站编码为GBK,通过这个接口传入参数为中文时返回的url3中有乱码。
于是从这个接口仅获取key值,其他的参数自行拼接
real_address = self.host1+'/yousheng/{}/{}/{}'.format(info['flei'],info['bookname'],info['filename'])real_address+key即为可以访问的音频地址
3.尝试使用python的类来写,代码可能稍微有点乱。
04
使用方法
这里讲一下成品文件的使用方法。
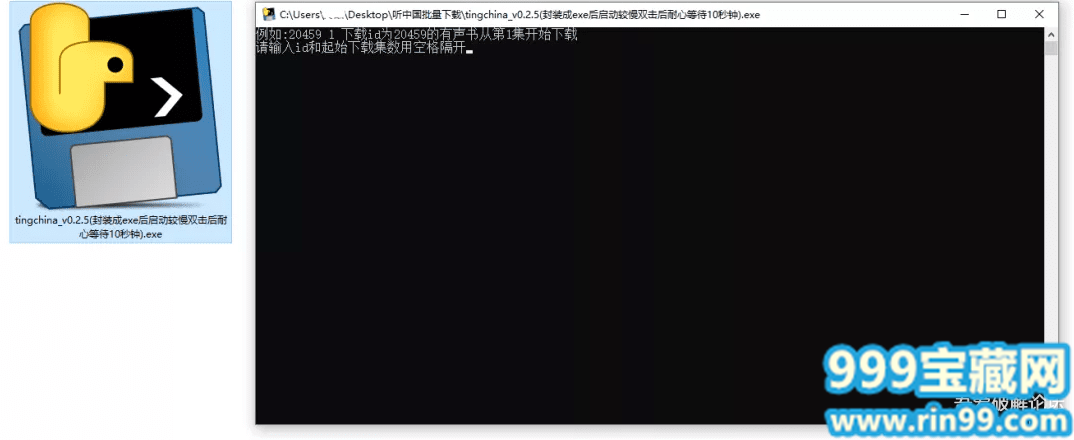
1.自己打包好之后,打开exe文件。

2.直接输入音频id和起始的下载集数,中间用空格隔开比如,输入:302371表示下载id为30237的音频,从第一集开始下载。
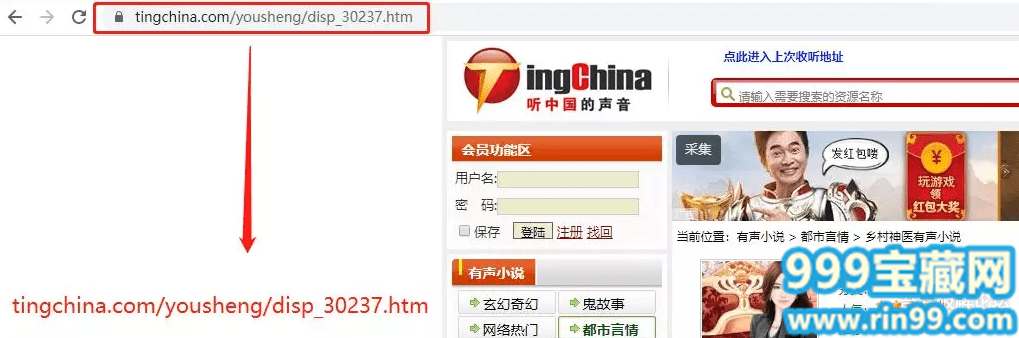
那如何看音频id呢?点击某一个音频后,看域名地址,如下图,30237就是这个音频的id。
3.输入后,巧回车键,即可开始下载。音频的下载位置就在此程序的同一级目录下,自动建立文件夹。
4.下载后的音频如下,时间长度没有任何问题,很完整。
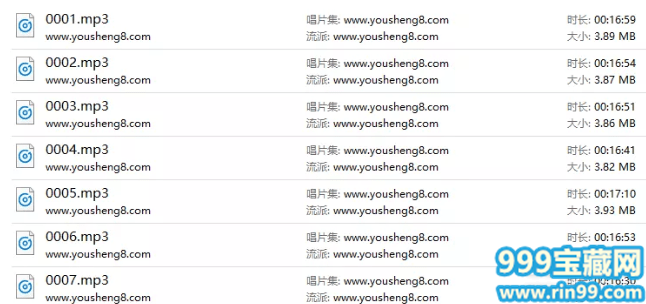
05
结语
[color=]希望大家新年快乐,多多发财,多多热心支持下
,不会的地方也可以在下面评论区留言,这个网站的音频资源很丰富想听什么音频可以来这里找,但是不推荐在网站上在线收听,广告太多,交互很不友好。成品下载链接
且下载受限制,需要开通会员所以才有了本文。感谢技术佛@老殁 |
评分
-
查看全部评分
|





 发表于 2020-1-12 12:38:00
发表于 2020-1-12 12:38:00












 发表于 2020-1-13 11:36:36
发表于 2020-1-13 11:36:36

