- 注册时间
- 2016-9-13
- 最后登录
- 2017-12-12
- 回帖
- 135
- 主题
- 317
- 精华
- 1
- 金币
- 1170
- 威望
- 0
- 股份
- 0
- 热心值
- 39
- 积分
- 1627

宝藏大学生
 
- 回帖
- 135
- 金币
- 1170
- 威望
- 0
- 积分
- 1627
- 股份
- 0
- 热心值
- 39
- 宝藏币
- 0
|
前言
在正常情况下(不使用其他工具或插件),Web端的bilibili似乎无法(彻底白嫖)下载视频,遂学习了如何利用Python爬虫下载b站视频(不包括会员视频),详情(手法)且看下文。
参考视频:https://www.bilibili.com/video/BV1Fy4y1D7XS
在分析b站网页源代码的过程中发现其视频和音频是分开的,下载后一个只有声音,一个只有画面,这显然不能满足我们的要求。解决方案是:利用 ffmpeg 这款强大的开源工具把下载后的音视频进行合并。故想要完美体验,先得下载安装并配置好 ffmpeg 。(到官网下载,解压后把文件夹内的bin 添加到环境变量)
Python中使用到的模块有:requests、re、json、subprocess、os
准备工作
视频的url比较显眼,容易获取。headers也好找,但还需要一重要信息。
通过浏览器(F12)查看分析目标网页,找到我们的下一目标,即视(音)频下载链接。
一番查找后,发现在head里的第四个script 标签内似乎有我们想要的东西。
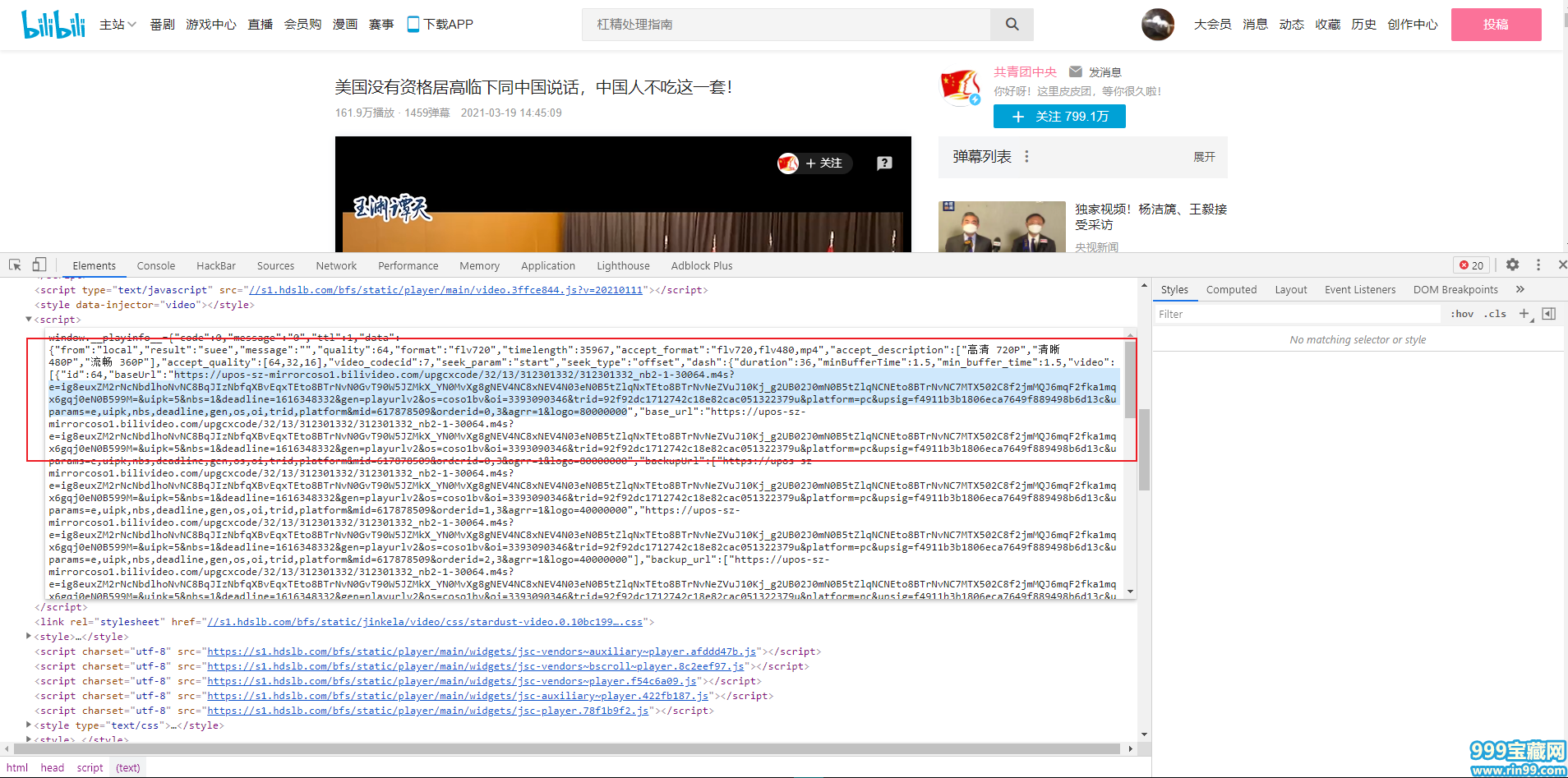
可访问此链接,却出现403,即没有权限访问此站。

这又怎么回事?查看Request Headers 信息,发现没有referer这一项,于是尝试在数据包中加上referer信息看能否访问。(这里直接上bp了)
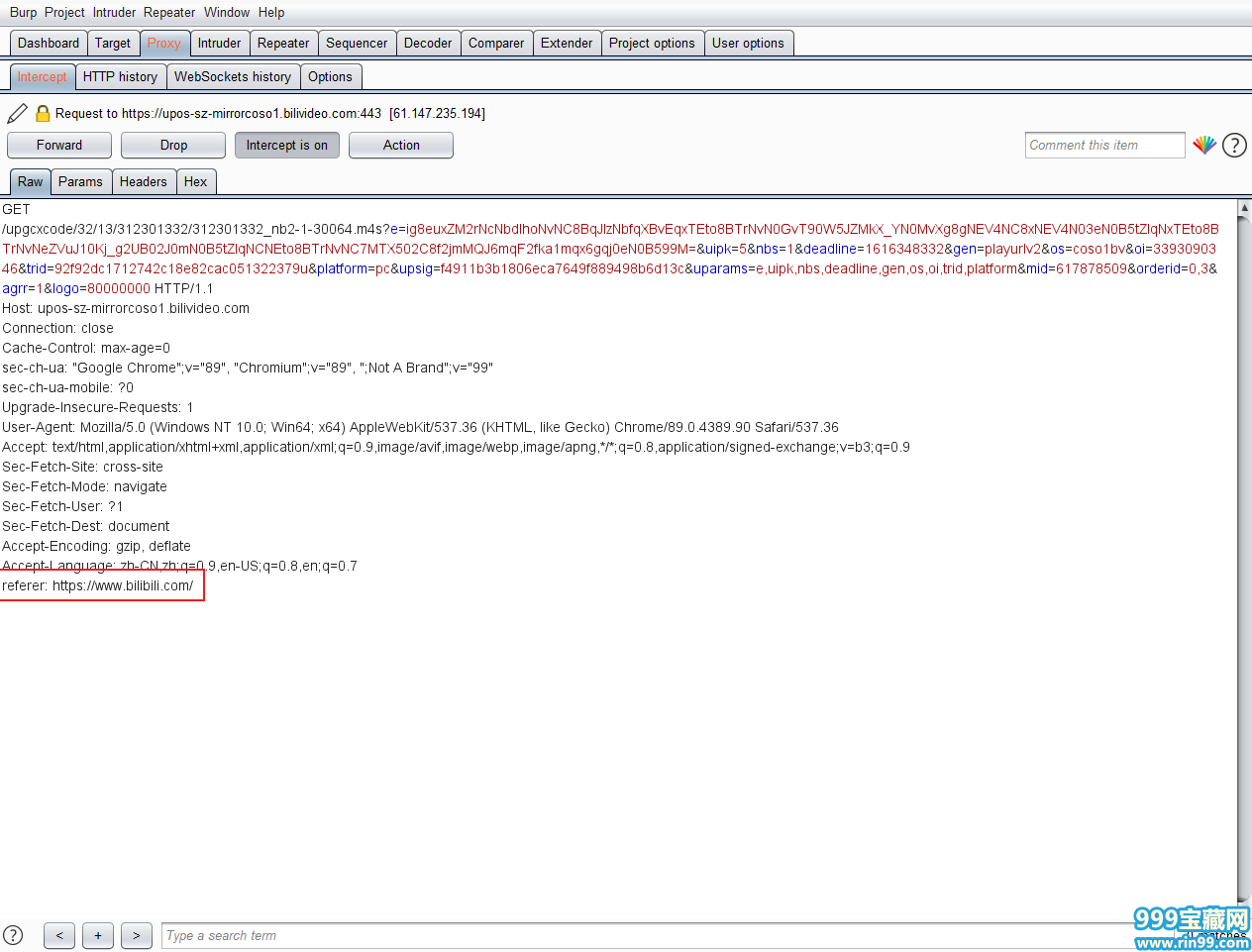
Forward后,出现文件下载页面。
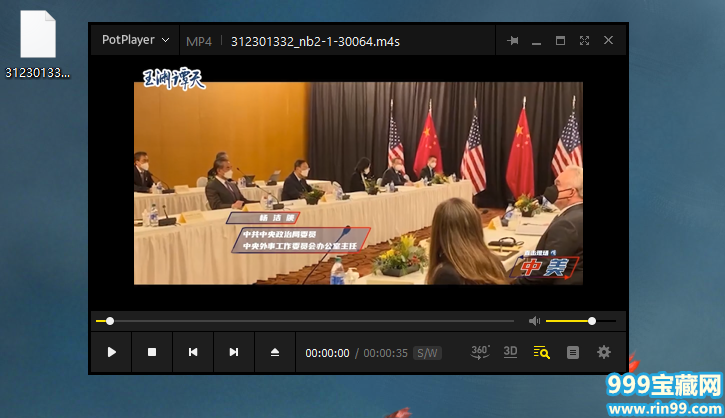
下载后打开改文件,确为目标视频。
获取数据
通过requests库向目标站点发起请求,请求需包含header、referer等信息,以伪装成是浏览器发出请求。如果服务器能正常响应,会得到一个Response,便是所要获取的页面内容。
测试代码:
import requestsheaders = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36","referer": "https://message.bilibili.com/"}def send_request(url): response = requests.get(url=url, headers=headers) #发送get请求,获得响应 return responsehtml_data = send_request("https://www.bilibili.com/video/BV1Qy4y147H1").textprint(html_data)
运行结果:
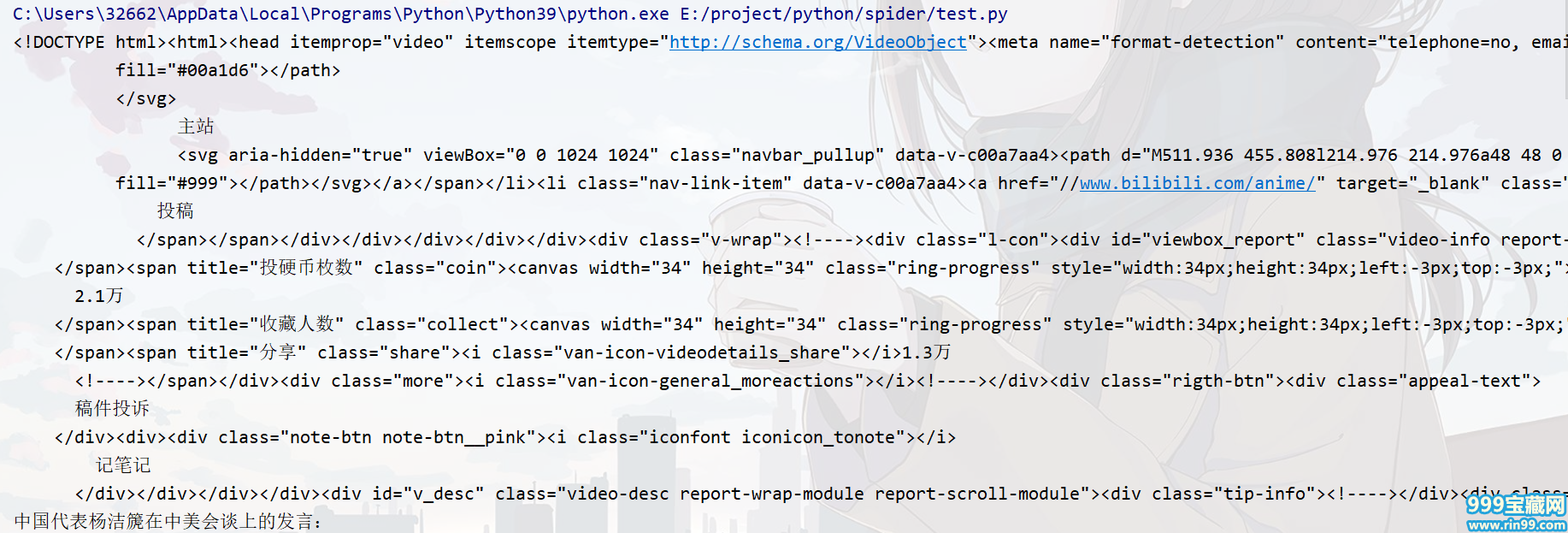
解析内容
得到的内容可能是HTML、json等格式,可以用页面解析库、正则表达式等进行解析。
title信息比较好找,就在head中。
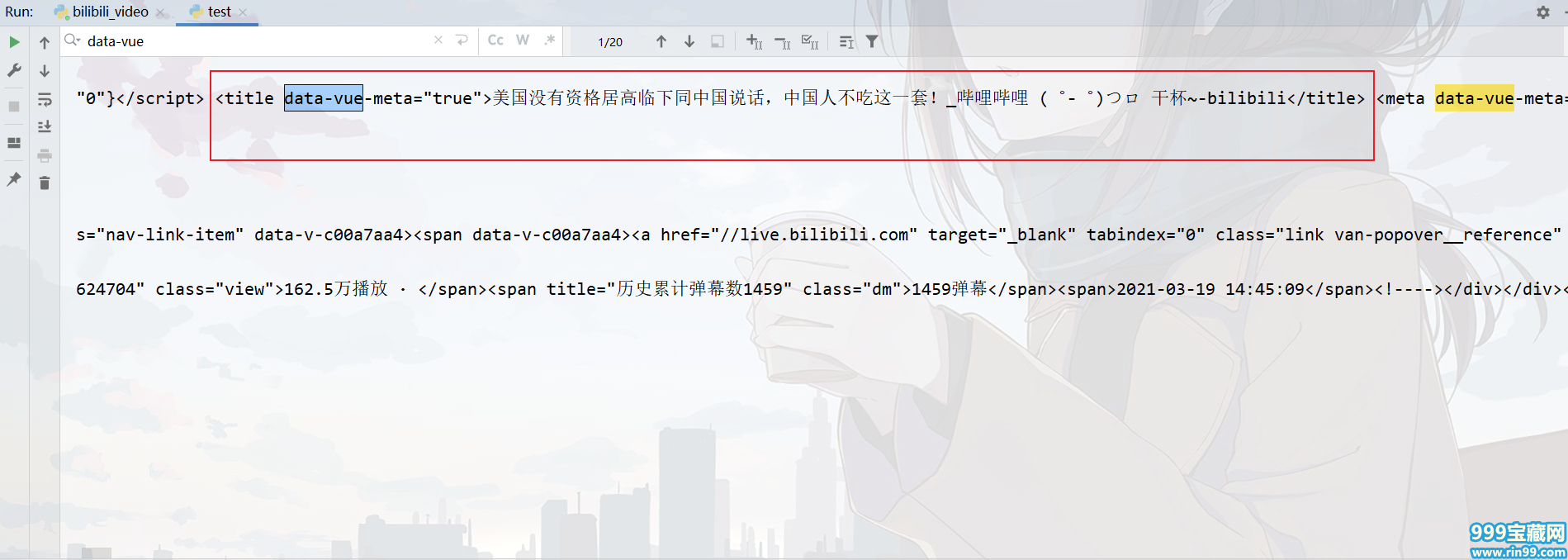
利用正则表达式对其进行提取。
title = re.findall('(.*?)',html_data)[0].replace("_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili",""
音视频下载链接在json数据中。
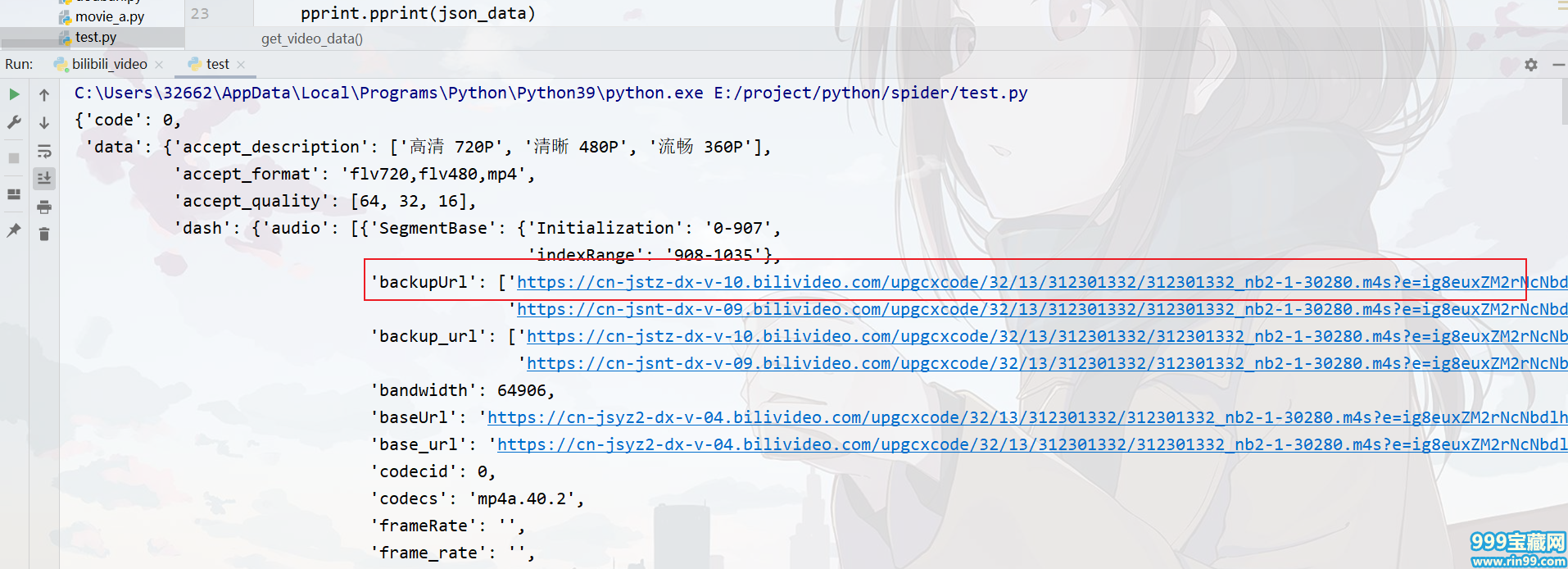
利用正则表达式和字典(列表)的“键”对其提取。
json_data = re.findall(r'',html_data)[0] json_data = json.loads(json_data) #解码 JSON 数据,返回 Python 字段的数据类型。 audio_url = json_data["data"]["dash"]["audio"][0]["backupUrl"][0] video_url = json_data["data"]["dash"]["video"][0]["backupUrl"][0]
测试代码:
import requestsimport reimport jsonimport pprintheaders = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36","referer": "https://message.bilibili.com/"}def send_request(url): response = requests.get(url=url, headers=headers) return responsedef get_video_data(html_data): title = re.findall('(.*?)',html_data)[0].replace("_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili","") json_data = re.findall(r'',html_data)[0] json_data = json.loads(json_data) #pprint.pprint(json_data) audio_url = json_data["data"]["dash"]["audio"][0]["backupUrl"][0] video_url = json_data["data"]["dash"]["video"][0]["backupUrl"][0] video_data = [title, audio_url, video_url] return video_datahtml_data = send_request("https://www.bilibili.com/video/BV1Qy4y147H1").textvideo_data = get_video_data(html_data)for item in video_data: print(item)
运行结果:

保存数据
通过下载链接,将音视频下载到本地并保存。
测试代码:
import requestsimport reimport jsonheaders = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36","referer": "https://message.bilibili.com/"}def send_request(url): response = requests.get(url=url, headers=headers) return responsedef get_video_data(html_data): title = re.findall('(.*?)',html_data)[0].replace("_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili","") json_data = re.findall(r'',html_data)[0] json_data = json.loads(json_data) audio_url = json_data["data"]["dash"]["audio"][0]["backupUrl"][0] video_url = json_data["data"]["dash"]["video"][0]["backupUrl"][0] video_data = [title, audio_url, video_url] return video_datadef save_data(file_name,audio_url,video_url): print("正在下载 " + file_name + "的音频...") audio_data = send_request(audio_url).content print("完成下载 " + file_name + "的音频!") print("正在下载 " + file_name + "的视频...") video_data = send_request(video_url).content print("完成下载 " + file_name + "的视频!") with open(file_name + ".mp3", "wb") as f: f.write(audio_data) with open(file_name + ".mp4", "wb") as f: f.write(video_data)html_data = send_request("https://www.bilibili.com/video/BV1Qy4y147H1").textvideo_data = get_video_data(html_data)save_data(video_data[0],video_data[1],video_data[2])
运行结果:


合并音视频
把分开的音频和视频进行合并。(几次测试下来,发现如果用视频标题作为文件名去执行ffmpeg命令会导致其出现错误,暂时没找到解决方法,后来试着将文件名先重命名为1.mp3、1.mp4这种简单的名字,可以完成合并,再删除之)
测试代码:
import requestsimport reimport jsonimport subprocessimport osheaders = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36","referer": "https://message.bilibili.com/"}def send_request(url): response = requests.get(url=url, headers=headers) return responsedef get_video_data(html_data): title = re.findall('(.*?)',html_data)[0].replace("_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili","") json_data = re.findall(r'',html_data)[0] json_data = json.loads(json_data) audio_url = json_data["data"]["dash"]["audio"][0]["backupUrl"][0] video_url = json_data["data"]["dash"]["video"][0]["backupUrl"][0] video_data = [title, audio_url, video_url] return video_datadef save_data(file_name,audio_url,video_url): print("正在下载 " + file_name + "的音频...") audio_data = send_request(audio_url).content print("完成下载 " + file_name + "的音频!") print("正在下载 " + file_name + "的视频...") video_data = send_request(video_url).content print("完成下载 " + file_name + "的视频!") with open(file_name + ".mp3", "wb") as f: f.write(audio_data) with open(file_name + ".mp4", "wb") as f: f.write(video_data)def merge_data(video_name): os.rename(video_name + ".mp3","1.mp3") os.rename(video_name + ".mp4","1.mp4") print("正在合并 " + video_name + "的视频...") subprocess.call("ffmpeg -i 1.mp4 -i 1.mp3 -c:v copy -c:a aac -strict experimental output.mp4", shell=True) os.rename("output.mp4", video_name + ".mp4") os.remove("1.mp3") os.remove("1.mp4") print("完成合并 " + video_name + "的视频!")html_data = send_request("https://www.bilibili.com/video/BV1Qy4y147H1").textvideo_data = get_video_data(html_data)save_data(video_data[0],video_data[1],video_data[2])merge_data(video_data[0])
运行结果:
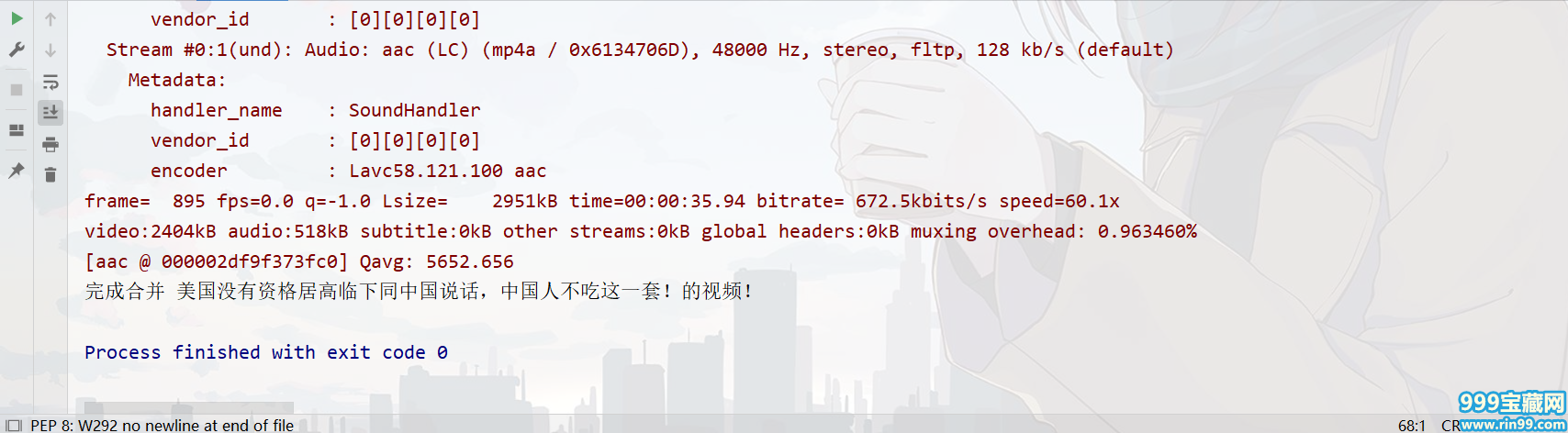
合并后视频正常播放,有声有色。
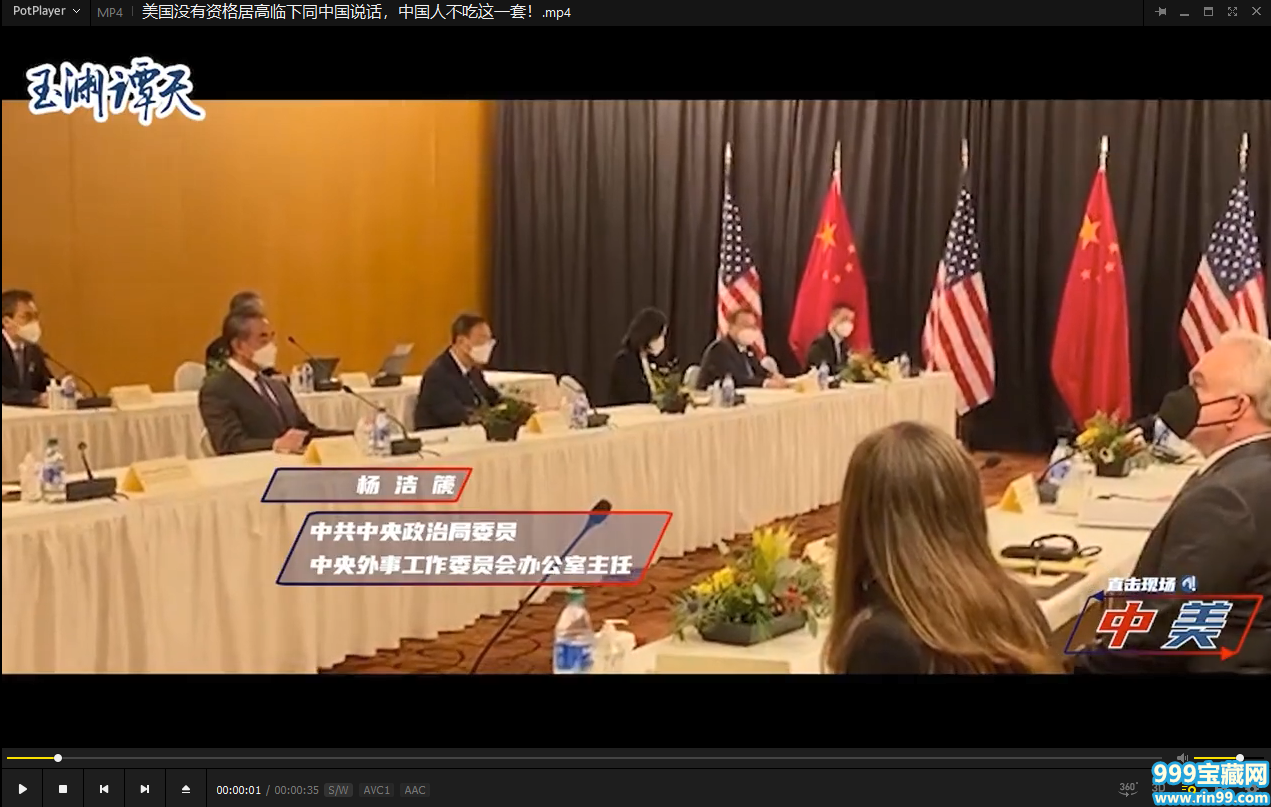
最终代码# -*- coding : utf-8 -*-# home.php?mod=space&uid=238618 : 2021/3/21 16:11# home.php?mod=space&uid=686208 : wawyw# home.php?mod=space&uid=267492 : bilibili_video.py# home.php?mod=space&uid=371834 : PyCharmimport requestsimport reimport jsonimport subprocessimport osheaders = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36","referer": "https://message.bilibili.com/"}def send_request(url): response = requests.get(url=url, headers=headers) return responsedef get_video_data(html_data): title = re.findall('(.*?)',html_data)[0].replace("_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili","") json_data = re.findall(r'',html_data)[0] json_data = json.loads(json_data) audio_url = json_data["data"]["dash"]["audio"][0]["backupUrl"][0] video_url = json_data["data"]["dash"]["video"][0]["backupUrl"][0] video_data = [title, audio_url, video_url] return video_datadef save_data(file_name,audio_url,video_url): print("正在下载 " + file_name + "的音频...") audio_data = send_request(audio_url).content print("完成下载 " + file_name + "的音频!") print("正在下载 " + file_name + "的视频...") video_data = send_request(video_url).content print("完成下载 " + file_name + "的视频!") with open(file_name + ".mp3", "wb") as f: f.write(audio_data) with open(file_name + ".mp4", "wb") as f: f.write(video_data)def merge_data(video_name): os.rename(video_name + ".mp3","1.mp3") os.rename(video_name + ".mp4","1.mp4") print("正在合并 " + video_name + "的视频...") subprocess.call("ffmpeg -i 1.mp4 -i 1.mp3 -c:v copy -c:a aac -strict experimental output.mp4", shell=True) os.rename("output.mp4", video_name + ".mp4") os.remove("1.mp3") os.remove("1.mp4") print("完成合并 " + video_name + "的视频!")def main(): url = input("输入bilibili视频对应的链接即可下载:") html_data = send_request(url).text video_data = get_video_data(html_data) save_data(video_data[0],video_data[1],video_data[2]) merge_data(video_data[0])if __name__ == "__main__": main()
效果:
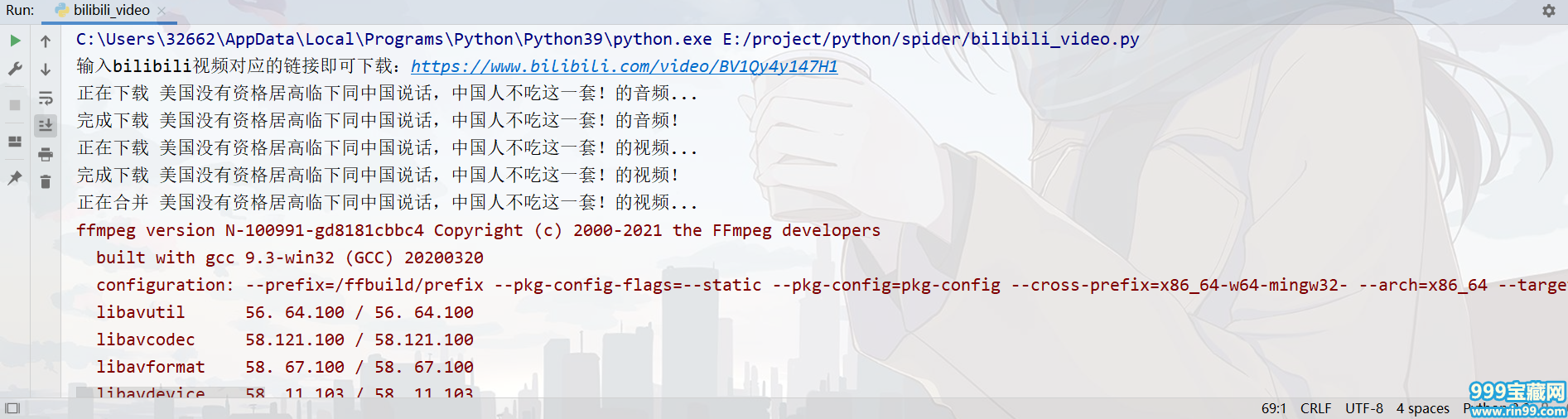
虽说这次是将白嫖进行到底了,但B站UP主们创作视频确实不易,我们也从中收获很多,能三连还是要多多支持下~
打包成exe
首先我们要先安装Pyinstaller,直接在cmd使用pip命令
pip install pyinstaller
然后,把ffmpeg和py文件放置到同一文件夹下。
因为ffmpeg是要一起打包的,需要对代码中的相应目录做小幅修改。修改后的代码如下:
import requestsimport reimport jsonimport subprocessimport osimport shutilheaders = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36","referer": "https://message.bilibili.com/"}def send_request(url): response = requests.get(url=url, headers=headers) return responsedef get_video_data(html_data): title = re.findall('(.*?)',html_data)[0].replace("_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili","") json_data = re.findall(r'',html_data)[0] json_data = json.loads(json_data) audio_url = json_data["data"]["dash"]["audio"][0]["backupUrl"][0] video_url = json_data["data"]["dash"]["video"][0]["backupUrl"][0] video_data = [title, audio_url, video_url] return video_datadef save_data(file_name,audio_url,video_url): print("正在下载 " + file_name + "的音频...") audio_data = send_request(audio_url).content print("完成下载 " + file_name + "的音频!") print("正在下载 " + file_name + "的视频...") video_data = send_request(video_url).content print("完成下载 " + file_name + "的视频!") with open(file_name + ".mp3", "wb") as f: f.write(audio_data) with open(file_name + ".mp4", "wb") as f: f.write(video_data)def merge_data(video_name): os.rename(video_name + ".mp3","1.mp3") os.rename(video_name + ".mp4","1.mp4") shutil.move("1.mp3","ffmpeg/bin/1.mp3") shutil.move("1.mp4","ffmpeg/bin/1.mp4") print("正在合并 " + video_name + "的视频...") os.chdir("ffmpeg/bin/") subprocess.call("ffmpeg -i 1.mp4 -i 1.mp3 -c:v copy -c:a aac -strict experimental output.mp4", shell=True) os.rename("output.mp4", video_name + ".mp4") os.remove("1.mp3") os.remove("1.mp4") shutil.move("%s.mp4"%video_name,"../../%s.mp4"%video_name) print("完成合并 " + video_name + "的视频!")def main(): url = input("输入bilibili视频对应的链接即可下载:\n") html_data = send_request(url).text video_data = get_video_data(html_data) save_data(video_data[0],video_data[1],video_data[2]) merge_data(video_data[0])if __name__ == "__main__": main()
修改好后,cmd切换到我们刚刚放文件的目录,执行如下命令:
Pyinstall -F -i bilibili.ico bilibili_video_download.py
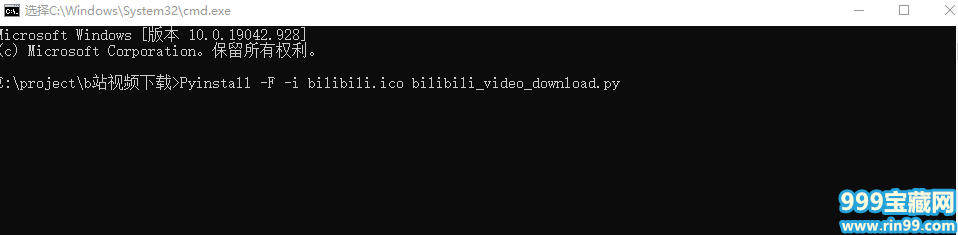
(这里-i bilibili.ico是对程序的图标进行设置,为可选项)
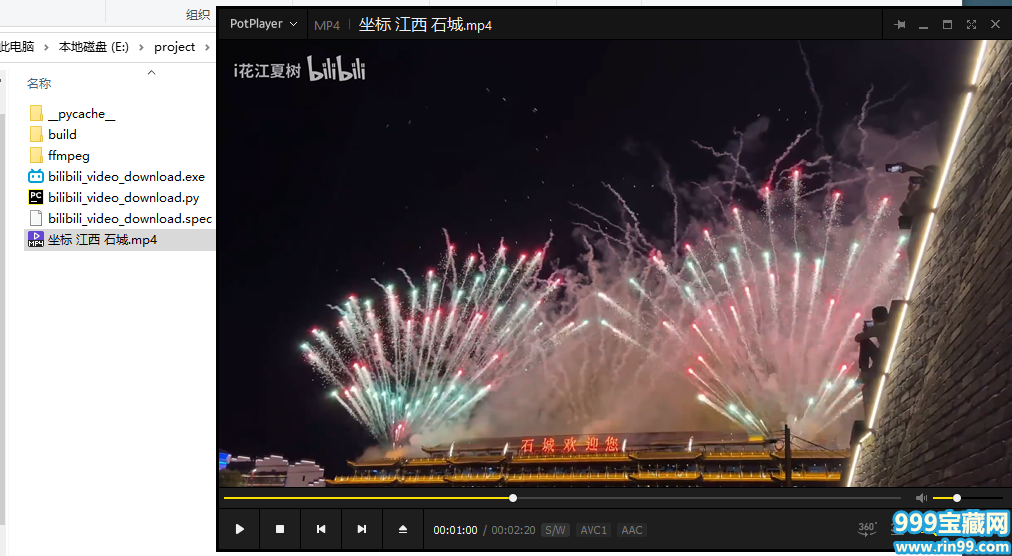
执行完毕会发现当前目录多了几个文件夹,打开其中名为dist的文件夹,里面生成了一个名为bilibili_video_download的exe应用程序,并且图标也是我们设置的图案。(这里要把exe文件移动到上一级目录,即ffmpeg的同级目录)

点击运行exe应用程序,输入视频URL即可下载。

下载完毕!
所有相关资源已放在下面的链接中,需要的朋友可以自取。(下载后解压此压缩包,运行bilibili_video_download.exe并输入视频对应链接即可完成视频下载 )
链接:
复制这段内容后打开百度网盘手机App,操作更方便哦
|
评分
-
查看全部评分
|





 发表于 2021-4-25 04:24:57
发表于 2021-4-25 04:24:57











 发表于 2021-4-25 14:05:03
发表于 2021-4-25 14:05:03

